# 内存对齐
<font style="background: yellow">
<font style="background:pink">
<font style="background: MediumSpringGreen">
2
3
# 目录
[TOC]
2022年6月24日,星期五,于编译器公司
- 总的来说,这类面试题,是不够严谨的,这个和具体的编译器实现有关。而编译器的实现又可能基于CPU啥的。
- 建议,面试的时候,自行#pragma pack(4)和8去进行考虑讲解
- 如果问到默认的对齐值,就说,和编译器版本和OS有关
# 0.参考资料『记忆』⭐️
- 1.转载传送门(PS:此文章中有错误的地方,下面自行改正了) (opens new window)
- 2.CSDN官方转载,技术让梦想更伟大 (opens new window)『很不错』
- 记忆下面的核心:已知
#pragma pack(n)就能全部解决- 1』32位编译器
#pragma pack(4),64位编译#pragma pack(8) - 2、3.结构体总大小为最大对齐数的整数倍(max(各个成员变量的由(规则2)获得的对齐数大小)) (每个成员变量都有自己的对齐数)『是的,这个才是核心!后边我对有个测试的判断,写错了』
- 比如理解就是
int类型在16位机器上,是2个字节和2个字节『而不是4个字节』double在32位机器上,是4个字节和4个字节『而不是8个字节』(2022年,6月24于编译器公司觉得,不对!)
- 注意:讲字节对齐的时候,不告知CPU位数和操作系统和编译器位数就是耍流氓!
- 1』32位编译器
# 1.内存对齐前述❎
原因:现代的计算机中,有一个内存对齐的要求
PS:现代计算机中内存空间都是按照字节划分的,所以图示中一个黑色的长条代表一个字节。
例:有些平台每次读都是从偶地址开始的 『笔者认为,也可以是从2的倍数,从4的倍数,8的倍数开始。。 如果一个int型(假设为32位系统)
- 1)如果他存放在偶地址开始的地方,那么一个CPU读的周期,就可以读出这个32bit的int
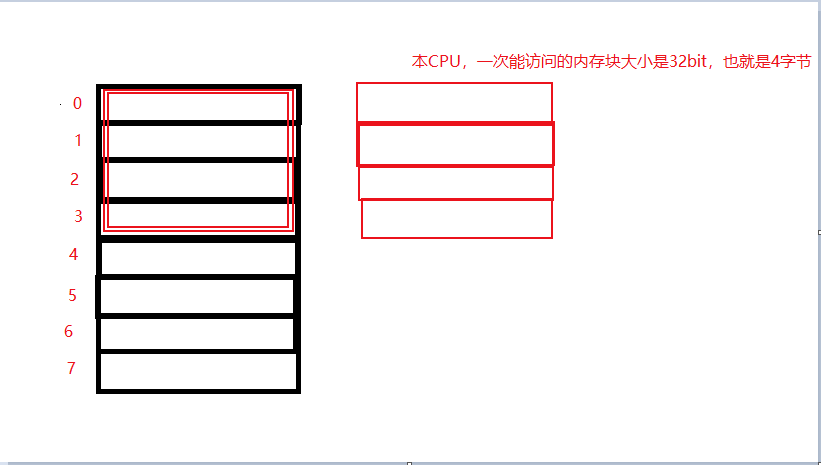
- 2)如果他存放在奇地址开始的地方,那么我们要是想要读取,蓝色的部分的int,我们的CPU需要读两个红色的框框。在第一个4字节块,剔除不想要的字节(0地址),然后从地址4开始读取下一个4字节块,同样剔除不要的数据(5,6,7地址),最后将留下的两块数据合并放入寄存器。也就是说这种情况CPU需要2个读周期,并且对两次读出的结果的高低字节进行拼凑才能得到这个32位bit的数据。
很显然,这个在读取的效率上下降了很多。
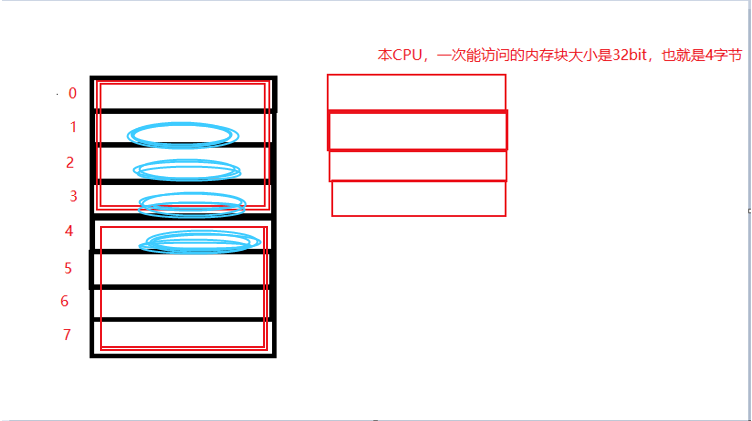
此处有疑惑
- Q:难道就不能直接从那个奇地址开始读吗?
- A:理论上讲,我们对任何类型的变量的访问可以从任何奇或者偶地址开始,这样是可以的。 但是,我们的硬件在设计的时候,CPU的底层访问实现的似乎就是这个,每次从偶地址开始读取。
总的来说,内存对齐一般是由于以下原因:
- 1)平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。(有的硬件的设计就是只支持从偶地址开始访问的)
- 2)性能原因(根本原因):数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问(前面我们的例子就是这样);而对齐的内存访问仅需要一次访问。
- 我们要提高CPU访问内存数据的效率的问题。
- 计算机访问内存一般是以内存块为单位的,块的大小是地址对齐的。如4,8,16字节对齐等。
- 一般来说对齐是跟CPU位数及CPU特性有关的,具体的比如X86-64支持1,2,4,8字节对齐.所以里面的讲的对齐主要还是取决于C语言中数据类型的大小。
PS:对齐值必须是2的幂次方,如1,2,4,8,16。如果一个变量按n字节对齐,那么该变量的起始地址必须是n的倍数。
每个特定平台上的编译器都有自己默认的“对齐系数”,可以通过设置
#pragma pack(n)告诉编译器,是n字节对齐。
# 1.1.是否可以强制不内存对齐?
- 可以,但是那样会导致CPU效率降低(X64的ABI文档里面也写了)
# 2.前置—可移植性(基本类型的对齐数)
《Java核心技术卷1》说道:与C和C++不同,Java规范中没有“依赖具体实现”的地方!基本数据类型大小以及有关运算都做了明确的说明!
- Java中int永远是32位的整数
- 而
在C和C++中,int可能是16位整数、32位整数、也可能是『编译器提供商』指定的其他大小。唯一的限制只是:int类型的大小不低于short int,并且不能高于long int - 在Java中,数据类型具有固定的大小、这消除了代码移植时令人头痛的问题
# 2.1.记忆『核心』⭐️
int,long int,short int 的宽度和机器字长及编译器有关,但一般都有以下规则(ANSI/ISO制订的)
sizeof(short int) <= sizeof(int)sizeof(int) <= sizeof(long int)short int至少应为16位(2字节)long int至少应为32位
| 数据类型 | 16位编译器 | 32位编译器 | 64位编译器 |
|---|---|---|---|
| char | 1字节 | 1字节 | 1字节 |
| 『指针』char* | 2字节 | 4字节 | 8字节 |
| short int | 2字节 | 2字节 | 2字节 |
| int | 2字节 | 4字节 | 4字节 |
| unsigned int | 2字节 | 4字节 | 4字节 |
| float | 4字节 | 4字节 | 4字节 |
| double | 8字节 | 8字节 | 8字节 |
| long | 4字节 | 4字节 | 8字节 |
| long long | 8字节 | 8字节 | 8字节 |
| unsigned long | 4字节 | 4字节 | 8字节 |
# 测试环境
[root@CentosLinux ~]# uname -m
x86_64
[root@CentosLinux ~]# uname -a
Linux CentosLinux 3.10.0-1127.19.1.el7.x86_64 #1 SMP Tue Aug 25 17:23:54 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
2
3
4
- cpu信息
lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 1
On-line CPU(s) list: 0
Thread(s) per core: 1
Core(s) per socket: 1
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 94
Model name: Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
Stepping: 3
CPU MHz: 2394.374
BogoMIPS: 4788.74
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 4096K
L3 cache: 28160K
NUMA node0 CPU(s): 0
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single fsgsbase bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx avx512f avx512dq rdseed adx smap avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 arat
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 2.实验观察内存对齐❎
例题5:(分析下面在32位编译环境的程序)
#include<stdio.h>
#pragma pack(2)
//要是不加#pragma pack(2),则是默认4字节对齐,我们其实可以看做#pragma pack(4)
struct{
char c1;
char c2;
int i;
}demo;
int main()
{
printf("%d\n",sizeof(demo));
return 0;
}
//输出为6 //因为加了#pragma pack(2),根据规则2可以知道也是6
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 3.结构体内存对齐规则『核心』
Tips:C语言和C++允许你用预编译来干预内存对齐
- 比如用
#pragma pack来干预。
- 比如用
不同平台上编译器的
pragma pack默认值不同。而我们可以通过预编译命令#pragma pack(n), n= 1,2,4,8,16来改变对齐系数。- 现代计算机读取数据的时候,都是一次性读取一个内存块,比如4字节。(更准确来说是与数据线根数有关,所以说,其实现在都是64位的CPU,一次性能够读取8字节)
一般内存块对齐方式『核心之一』:
- 16位CPU机器默认2字节对齐『
#pragma pack(2)』 - 32位CPU机器默认4字节对齐『
#pragma pack(4)』 - 64位CPU机器上的64位编译器默认8字节对齐『
#pragma pack(8)』
- 16位CPU机器默认2字节对齐『
内存对齐又分为『自然对齐』和『规则对齐』
# 3.3.自然对齐和规则1:基本类型对齐
指的是将对应变量类型存入对应地址值的内存空间,即数据要根据其数据类型存放到以其数据类型为倍数的地址处。
- 例如 char 类型占1个字节空间,1的倍数是所有数,因此可以放置在任何允许地址处
- 而int类型占4个字节空间,以4为倍数的地址就有0,4,8等。
编译器会优先按照自然对齐进行数据地址分配。
基本类型的对齐值就是其
sizeof获得值;- 『坑点:比如
int在16位的编译器上是sizeof(int)=2』
- 『坑点:比如
我们在进行基本类型对齐的同时,我们要尽量保证每个变量整体能放到1个或者2个内存块当中,并且要尽可能的小。也就是能放在1个内存块,绝不放2个,否则会降低效率,比如先前图片中int放的位置。
对于标准数据类型,它的地址只要是它的长度的整数倍就行了。
非标准数据类型按下面的原则对齐:
数组:按照基本数据类型对齐,第一个对齐了后面的自然也就对齐了。
联合:按其包含的长度最大的数据类型对齐。
结构体:结构体中每个数据类型都要对齐。
# 3.2.规则对齐和规则2:struct和union的数据成员对齐规则
结构(struct)和联合(union))的数据成员对齐规则:
- 在数据成员完成各自对齐之后,结构和联合本身也要进行对齐。
- 1—未改变默认规定对齐值,对齐将按照结构或联合整体
sizeof和默认的机器字节对齐中,比较小的那个进行; - 2—修改了默认规定对齐值,比如
#pragma pack(n),对齐将按照#pragma pack(n)指定的数值和结构(或联合)sizeof获得值中小的那个进行;
以『结构体』为例就是在自然对齐后,编译器将对『自然对齐』产生的『空隙内存』填充无效数据,且填充后结构体占内存空间为结构体内占内存空间最大的数据类型成员变量的整数倍。
# 1、难点1—double『测试坑』⭐️『其实说的就是“可移植性”』
- 我们知道32位处理器一次只能处理32位也就是4个字节的数据,而 double 是8字节数据类型,这要怎么处理呢?
- 『如果是64位处理器,8字节数据可以一次处理完毕』,而在32位处理器下,为了也能处理 double8 字节数据,在处理的时候将会把 double 拆分成两个4字节数进行处理,从这里就会出现一种情况如下:
typedef struct test_32
{
char a;
char b;
double c;
}test_32;
2
3
4
5
6
- 这个结构体在32位下所占内存空间为12字节,只能拆分成两个4字节进行处理,所以这里规则对齐将判定该结构体最大数据类型长度为4字节,因此总长度为4字节的整数倍,也就是12字节。
- 这个结构体在64位环境下所占内存空间为16字节,而64位判定最大为8字节,所以结果也是8字节的整数倍:16字节。这里的结构体中的double没有按照自然对齐放置到理论上的8字节倍数地址处,我认为这里编译器也有根据规则对齐做出相应的优化,节省了4个多余字节
测试代码如下:环境『Linux64位』
#include<bits/stdc++.h>
using namespace std;
typedef struct test_32
{
char a;
char b;
double c;
}test_32;
int main()
{
cout<<sizeof( test_32)<<endl;
cout<<offsetof(test_32,a)<<endl;
cout<<offsetof(test_32,b)<<endl;
cout<<offsetof(test_32,c)<<endl;
return 0;
}
//输入是16
//0
//1
//8
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
更改字节对齐之后『反向知晓,64位Linux的g++默认对齐数是8字节』
#include<bits/stdc++.h>
#pragma pack(4)
using namespace std;
typedef struct test_32
{
char a;
char b;
double c;
}test_32;
int main()
{
cout<<sizeof( test_32)<<endl;
cout<<offsetof(test_32,a)<<endl;
cout<<offsetof(test_32,b)<<endl;
cout<<offsetof(test_32,c)<<endl;
return 0;
}
//输入是12
//
//0
//1
//4
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
我的猜想:
1、默认字节对齐的本质:CPU一次性寻址的字节长度
2、自然对齐中min(默认的对齐数,这个基本类型的字节数)『设置4字节对齐之后,看到了,本猜想正确』
3、本次测试,好像推翻了『规则对齐。。。。
规则对齐改为??规则对齐,取我们实际上》》》》。。。不清楚
我觉得可这么想,由于min(4,double)获得的是4,所以在自然对齐的时候,我们被迫将double分成两半
然后,规则对齐的时候,虽然结构体中最大显然是8,应该是8的倍数,但是被『编译器优化了』觉得后面的『补充不需要了,所以,才采取的12,而不是16,
进一步猜测:补全空格,只补充中间的,不补充最末尾的?『这个猜想,和下面的黄色部分,我觉得是对的,模型建立完毕』
修正知道:对齐长度『长于』struct中的类型长度『最长』的值时,设置的对齐长度等于无用
故当我们将 #pragma pack 的n值小于『所有数据成员长度』的时候,结果将改变。
或许上面就是,我们使用pack(4)之后是12的原因??
# 2、数组『1个易错』
- 对齐值为:min(数组元素类型,编译器默认对齐长度/修改后)。
- 易错:数组对齐的长度是按照『数组成员类型』长度来比对的
- 但数组中的元素是连续存放,存放时还是按照数组实际的长度。如char t[9],对齐长度为1,实际占用连续的9byte。然后根据下一个元素的对齐长度决定在下一个元素之前填补多少byte
# 3、嵌套的结构体
struct A
{
......
struct B b;
......
};
//对于B结构体在A中的对齐长度为:
//min( B结构体的对齐长度 , 编译器默认对齐长度/修改后 )
2
3
4
5
6
7
8
# 3.3.综合方法
#pragma pack可以修改,『编译器默认对齐数』,修改之后,下面的那个对齐规则一律换成改后的!
# 1、首先『自然对齐』
- 1.第1个数据成员在『结构(struct)/联合(union)』变量offset偏移量为0 的地址处,也就是第一个成员必须从头开始。『原因:很显然,1,2,4,8的共同的倍数都是0,因为0乘以任何数都是0』
- 2.其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。对齐数为『编译器默认的对齐数』与该成员大小中的较小值(min(编译器默认对齐数,成员变量大小))。『自然对齐,审核正确』
- Linux中gcc和g++编译器,32位默认对齐数是4字节对齐。64位默认字节对齐数是8字节对齐。(后续有证明,注意,参考的“脚本之家”那个有误)此外默认对齐数可以通过#pragma pack()修改,但修改只能设置成1,2,4,8,16。
# 2、然后『规则对齐』
- 3.结构体总大小为最大对齐数的整数倍(max(各个成员变量的由(规则2)获得的对齐数大小))。(每个成员变量都有自己的对齐数)『规则对齐,应该错误,应该不是由规则2获得的,而是直接所以成员变量』
- 4.如果嵌套结构体,被嵌套的结构体对齐到『自己的最大对齐数』的整数倍处,(其实就是,我们将这个结构体也看作1个普通的类型 变量,这个思想有的像『递归』的定义『『『如果一个结构里有某些结构体成员,则结构体成员要从其内部"最宽基本类型成员"的整数倍地址开始存储』』』)结构体的整体大小就是所有最大对齐数(包含嵌套结构体的对齐数)的整数倍。
其他:可借助,C语言头文件中
#include<stddef.h>中函数offsetof观察现象
# 3.4.坑点:
- 结构体中union等,要是没有实例化,并且没有其他元素,那么不用算他占的大小
- 如果,仅仅只有它,需要算1个字节,毕竟如果不算,那就不好表述struct了 『类似问,空class是多大』
# 5.杠筋?
# 5.1.测试环境(推翻第2条规则)♻️??
- 64位的CPU
- 64位的OS,装的64位的DevC++「无伤大雅」
- 但是编译器选择
DevC++ 32bit Release版本 - 运行环境,还是在这个64位的机器上
#include<bits/stdc++.h>
using namespace std;
struct xx
{
long long _x1;
char _x2;
int _x3;
char _x4[2];
static int _x5;
};
int xx::_x5;
int main()
{
printf("%d\n",sizeof(xx));
printf("%d\n",offsetof(xx,_x1));
printf("%d\n",offsetof(xx,_x2));
printf("%d\n",offsetof(xx,_x3));
printf("%d\n",offsetof(xx,_x4));
printf("%d\n",offsetof(xx,_x4[1]));
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
测试
24
0
8
12
16
17
2
3
4
5
6
# 5.1.1.『看似解释不通?』,如果按照先前的解释方式:
_x1 对齐数 min(long long,4)=4 0-7
_x2 对齐数 min(char,4)=1 8
_x3 对齐数 min(int,4)=4 12-15
_x4 对齐数 min(char,4)=1 16-17 (易错点,注意是char,而不是2个char)
整体字节对齐
max(4,1,4,1)=4
那么20字节就OK了,但是这样不对????为什么??『我的解释在后边!!』
2
3
4
5
6
7
# 5.1.2.最新解释
_x1 对齐数 min(long long,4)=4 0-7
_x2 对齐数 min(char,4)=1 8
_x3 对齐数 min(int,4)=4 12-15
_x4 对齐数 min(char,4)=1 16-17
整体字节对齐
max(long long,char ,int , char)=8
那么24字节才OK
2
3
4
5
6
7
8
- 结构体的最终大小必须是结构体最大简单类型的整数倍???
- A:2021年7.12解释:
- 并不是的,我的理解是由于CPU是64位的,所以还是默认
#pragma pack(8),编译器说32位也没用。 - 『原因:你如果在前面进行强制的
#pragma pack(4),你就发现,答案是20而不是24,所以,我猜测这个是CPU的原因』 - CPU的位数很重要,或许决定了
#pragma pack()的数字
# 5.1.3.alignof好的测试
- alignof : 获取地址对齐的大小,POD里面最大的内存对其的大小。
- C 的 _Alignof 和 C++ 的 alignof 可以获得类型的对齐。
C语言中的_Alignof的对齐 (opens new window)
- 环境64位CPU,64位编译器
struct node
{
//char ss;
struct temp
{
char a;
int b;
double c;
} t;
};
cout<<"alignof(node):"<< alignof(node)<<endl;
cout<<sizeof(node)<<endl;
//alignof(node):8
//16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
- 如果加上
char ss;
//alignof(node):8
//24
2
# 3.典例解释
# 3.1.单个struct『Good解释⭐️
# 3.1.1.可移植性
在一个16位的机器,以下结构由于边界对齐浪费了多少空间()
复制代码
struct{
char a;
int b;
char c;
}
正确答案: D 你的答案: D (正确)
8
4
6
2
2
3
4
5
6
7
8
9
10
11
12
解释:
- 由于可移植性导致:
16位的机器上默认是2字节对齐『#pragma pack(2)』!那么该种机器中int只用2Byte,并不是什么int 在16位上要拆分为2个short的???『好像也不对,因为用后面的也能解释是2,!!!,但是《C++Primer》规定int最小是可以有16位』 - 1、自然对齐,min(char,『
#pragma pack(2)』)=1,所以a是1个字节放在[0,0] - 2、自然对齐,min(int(注意,此机器上是2),『
#pragma pack(2)』)=2,所以放在[2,3] - 3、自然对齐,min(char,『
#pragma pack(2)』)=1,所以c是1个字节放在[4,4] - 4、规则对齐,是max(1,2,1)=2,所以是2的倍数,最接近是6,就是[0,5]
然后,char+int(此机器上是2)+char=6个字节
- 8-6=2个字节浪费
# 3.1.2.面试记录
- 测试环境『64位编译器,,我觉得默认是64位CPU』
// 你必须定义一个 `main()` 函数入口。
//测试环境是:64位gcc编译器下输出
#include<stdio.h>
class A
{
union test
{
int aa;
int bb;
char *cc;
};//徐晃一枪,没有变量被定义,仅仅是“声明”
int a;
short b;
int c;
char d;
};
class B
{
double a;
short b;
int c;
char d;
};
int main()
{
printf("%d\n",sizeof(A));
printf("%d\n",sizeof(B));
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
64位gcc下输出
16
24
2
解释16原因:
64位的gcc编译器下对齐是『
#pragma pack(8)』坑点:union 没有初始化,但是struct中还有其他成员,我们就可以不用给它分配空间来占位置『如果只有它,我们需要1来占位』
min(int(4) , 『#pragma pack(8)』)=4字节对齐,int 占据前4个min(short(2),『#pragma pack(8)』)= 2字节对齐,short仅接着据2『后面,我们发现还要填补充』min(int(4) , 『#pragma pack(8)』)=4字节对齐,但是此时开始的位置不是4的倍数!『所以给前面的填pack』然后int 占据4个min(char(1) , 『#pragma pack(8)』)=1字节对齐,char紧接着占据1个 『后面,我们发现还要填补充』- 这个时候,我们发现,获得的是13个字节
接着,结构体总大小进行对齐『我们需要采用前面弄到的
- max(4,2,4,1)=4发现,最大对齐数是4
- 那么,我们知道最近的是16
解释24的原因:
- 64位的gcc编译器下对齐是『
#pragma pack(8)』
| 自然对齐 | 占用的大小 | 是否有补丁 |
|---|---|---|
min(double(8) , 『#pragma pack(8)』) =8字节对齐 | double占据前8个 | 0 |
min(short(2),『#pragma pack(8)』)= 2字节对齐 | short仅接着据2『后面,我们发现还要填补充』 | 2 |
min(int(4) , 『#pragma pack(8)』) =4字节对齐, | 但是此时开始的位置不是4的倍数!『所以给前面的填pack』然后int 占据4个 | 0 |
min(char(1) , 『#pragma pack(8)』) =1字节对齐 | char紧接着占据1个 『后面,我们发现还要填补充』 |
这个时候,我们发现,获得的是13个字节
接着,结构体总大小进行对齐『我们需要采用前面弄到的表格中第1列的值来求max』
- max(4,2,4,1)=4发现,最大对齐数是4
- 那么,我们知道最近的是16
# 3.2.单个union『复杂内存对齐分析(面试)』
- 测试环境『64位编译器,,或许默认64位CPU』
#include<bits/stdc++.h>
using namespace std;
struct one
{
char a;//1->内存对齐(4)
long b;//4
char c;
union test
{
int aa;
char bb;
};//没有实例化,不用管
double k;
int * p;//32位机器
};
struct two
{
union test
{
int aa;
char bb;
}demo;
};
struct three
{
union test
{
int aa;
char bb;
};
};
struct four
{
int a;
int b;
int c;
double d;
}_four;
int main()
{
//注意
printf("sizeof(long)=%d\n",sizeof(long));
one _one;
printf("%d\n",sizeof(_one));
two _two;
printf("%d\n",sizeof(_two));
three _three;
printf("%d\n",sizeof(_three));
int * p;
printf("%d\n",sizeof(p));
printf("%d\n",sizeof(_four));
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
- 测试环境32位CPU
- 『例子很好』题目传送门 (opens new window)
struct test
{
int ml;
char m2;
float m3;
union uu
{
char ul[5];
int u2[2];
} ua;
} myaa;
问32位机器下sizeof(struct test )
答:20
2
3
4
5
6
7
8
9
10
11
12
13
14
解释:
联合体的解释:
min( char(1), #pragma pack(4) )=1,我们的u1的5个元素,依次放到[0-4]min( int(4), #pragma pack(4) )=4,我们的u2的2个元素,依次从[0-7]『注意,是从头开始!』然后,我们发现,最长的占用了8个Byte
- 接下来:规则对齐,
max(1,4)=4,发现8是合理的,那么就占用8『注意,这个union整体的对齐数就是规则对齐数得到的——4『不要相成是8哈!!容易错』』
- 接下来:规则对齐,
union外边的
- int m1 4个
- char m2 1个
- float m3 4个 按照规则2和3,我们要按照默认的4字节对齐来对这些在结构体中重排列 m1 offset=0-3 m2 offset=4 offset=5-7不用,但是占领 m3 offset=8-11 union offset=12-19 总共,占用5个内存块,一个20个字节。
# 3.3.单个位段
- 可能嵌入式和网络编程中会用到这种用法:位段(也叫位域)一种特殊的类结构体语法
#include<stdio.h>
struct
{
int a:8;
int b:2;
int c:5;
}ab;
int main()
{
printf("%d\n",sizeof(ab));
return 0;
}
//输出4
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 问题:sizeof(long)是4还是8的不同是由不同编译器决定的,还是操作系统的位数,还是电脑的位数,还是C的标准
- 有人回答:这个是由编译器决定的,有的是32位编译器,有的是64位编译器,有的是标准C编译器,有的是C++编译器,都有可能不同
- 『正确吗???』
# 3.4.数组和指针组合『难题』
以下代码打印的结果是(假设运行在 64 位计算机上):
struct st_t {
int status;
short *pdata;
char errstr[32];
};
st_t st[16];
char *p=(char *)(st[2].esstr+32);
printf(“%d”,(p-(char *)(st)));
//题目来自——牛客网
2
3
4
5
6
7
8
9
10
//上面这道题,我们暂时不分析最后的结果,我们只分析在64位的机器下的这个结构体占用的字节。
因为是64位环境下,所以默认对齐方式是8字节为一个内存块
int status;虽然int只占用4个 由于后面的指针八个字节放不下 填补不了空位 所以对其要八个字节(后面的4个为对齐位)
short *pdata;这个指针会占用8个字节
char errstr[32]; 占用32个字节
- 所以一共占用 8+8+32=48个字节
char *p=(char *)(st[2].esstr+32),p实际指向了st[3]
则p-(char *)(st)),即为&st[3]-&st[0],占用空间为3个结构体的大小,即3*48=14
# C++反汇编与逆向分析技术揭秘-内存对齐P207
Q1:为什么在class中不能定义自身的对象呢?
因为class需要在申请内存的过程中计算出自身的实际大小,以用于实例化。(反汇编代码中体现了)
这样就导致:如果在class中定义了自身的对象,在计算各数据成员的长度时,又会回到自身,这样就形成了递归定义,而这个递归并没有出口,是一个无限的循环递归定义,综上不得行。
Q2:但是在class中能定义自身类型的指针
因为任何类型的指针在32位下所占的内存大小始终为4字节,等同于一个常量值,因此将其作为class的数据成员不会影响长度的计算。
# 1.假式-计算公式
对象长度 = sizeof(数据成员1) + sizeof(数据成员2) + ... + sizeof(数据成员n)
表面看上面公式没有问题,但对象的大小计算远远没有这么简单。
即时class中没有继承和虚函数的定义,仍然有3种特殊情况能推翻此公式:
# 1.1.空class
- 1
空类中没有任何数据成员,按照该公式计算得出的对象长度为0字节。类型长度为0,则此类的对象不占据内存空间。而实际情况是,空类的长度为1字节。如果对象完全不占用内存空间,那么空类就无法取得实例对象的地址,this指针失效,因此不能被实例化。
而类的定义是由成员数据和成员函数组成,在没有成员数据的情况下,还可以有成员函数,因此仍然需要实例化,分配了1字节的空间用于类的实例化,这1字节的数据并没有被使用。
# 1.2.静态数据成员
当类中的数据成员被修饰为静态时,对象的长度计算又会发生变化。
虽然静态数据成员在类中被定义,但它与静态局部变量类似,存放的位置和全局变量一致。
只是编译器增加了作用域的检查,在作用域之外不可见,同类对象将共同享有静态数据成员的空间,详细内容请参见9.3节。
# 1.3.内存对齐
总结:
由于存在内存对齐,所以要额外分析。
另外,各编译器厂商的实现也有所不同,应详细阅读相关文档。
# 1.3.1.结构体(成员)对齐值的问题
- 在为结构体和类中的数据成员分配内存时,结构体中的当前数据成员类型长度为
M,指定的对齐值为N,那么实际对齐值为q= min(M, N),其成员的地址安排在q的倍数上。如以下代码所示:
struct tagTEST{
short sshort;//应占2字节内存空间,假设所在地址为ox0012F74
int nInt;//应占4字节内存空间
};
2
3
4
5
数据成员sShort的地址为0x0012FF74,类型为short,占2字节内存空间。VC++ 6.0指定的对齐值默认为8,short 的长度为2,于是实际的对齐值取较小者2。所以,short 被分配在地址0x0012FF74处,此地址是2的倍数,可分配。此时,轮到为第二个数据成员分配内存了,如果分配在sShort后,应在地址0x0012FF76处,但第二个数据成员为int类型,占4字节内存空间,与指定的对齐值比较后,实际对齐值取int类型的长度4,而地址0x0012FF76不是4的倍数,需要插入两个字节填充,以满足对齐条件,因此第二个数据成员被定义在地址0x0012FF78处,如图9-2所示。
# 1.3.2.对齐值对(结构体整体)大小的影响
上述示例讲到了结构体成员对齐值的问题,现在讨论一下对齐值对结构体整体大小的影响。如果按VC++ 6.0默认的8字节对齐,那么结构体的整体大小要能被8整除,如以下代码所示:
struct{
double dDouble;
/1所在地址:Ox0012PFO0~ox0012FFO8之间,占8字节
int
nint;
1/所在地址:0x0012FFO8~0x0012FFOC之间
占4字节
shortsshort ;
1/所在地址:0x0012FFOC-0x0012FF10之间
占2字节
};
2
3
4
5
6
7
8
9
10
11
12
但是,并非设定了默认对齐值就将结构体的对齐值锁定。如果结构体中的数据成员类型最大值为M,指定的对齐值为N,那么实际对齐值为min(M, N),如以下代码所示:
struct{
char cchar;
/应占1字节内存空间,如所在地址为Ox0012FFO0
int nInt;
1/应占4字节内存空间
short ashort;
1/应占2字节内存空间
};
2
3
4
5
6
7
8
9
随后定义的数据成员sShort应该使用6字节的空数据对齐。
VC++ 6.0通过检查发现,结构中最大的类型为nInt数据,占4字节空间,于是将对齐值由8调整为4,重新调整后,sShort 只需要填充2字节的空白数据就可以实现对齐。
# 1.3.3.修改默认的对齐值
既然有默认的对齐值,就可以在定义结构体时进行调整,VC++6.0中可使用预编译指令#pragma pack(N)来调整对齐大小。修改以上示例,调整对齐值为1,如以下代码所示:
#pragma pack (1)struct{
char cChar;
1/应占1字节内存空间
int nInt;
1/应占4字节内存空间
short sshort;
I/应占2字节内存空间
};
2
3
4
5
6
7
8
9
使用pack修改对齐值也并非一定会生效,与默认对齐值一样,都需要参考==结构体中的数据成员类型==。
- 当设定的对齐值大于结构体中的数据成员类型大小时,此对齐值同样是无效的。(显然)
- 对齐值的计算流程换个说法是:将设定的对齐值与结构体中最大的基本类型数据成员的长度进行比较,取两者之间的较小者。
# 1.3.4.结构体(的数组成员)
当结构体中以数组作为==成员==时,将根据数组元素的长度计算对齐值,而不是按数组的整体大小去计算,如以下代码所示:
# 1.3.4.结构体(的结构体成员)
当结构体中出现结构体类型的数据成员时,不会将嵌套的结构体类型的整体长度参与到对齐值计算中,而是以嵌套定义的结构体(它本身最终)所使用的对齐值进行对齐,如以下代码所示:
struct tagone{
char cchar; //占1字节内存空间
char cArray [4];//占5字节内存空间
short sshort;//占2字节内存空间
};
struct tagTwo{
int nInt ; //占4字节内存空间
tagone one; // 占8字节内存空间
};
2
3
4
5
6
7
8
9
10
在以上结构中,虽然tagOne结构占8字节大小,但由于其对齐值为2,因此tag Two结构体中的最大类型便是 int,以4作为对齐值。所以,结构tagTwo的总大小并非以8字节对齐的16字节,而是以4字节对齐的12字节。
# 2.总结上述
- 《C++反汇编与逆向分析技术揭秘》,P209-P212
内存对齐步骤
- 1、在为结构体和类中的数据成员分配内存时,结构体中的当前数据成员类型长度M,指定的对齐值为N,那么实际对齐值为**==q=min(M , N)==**,其成员的地址安排在q的倍数上「P209」
- 2、讨论一下对齐值对结构体整体大小的影响。并非设定了默认对齐值就将结构体的对齐值锁定。如果**==结构体中数据成员类型最大值为M==,指定的对齐值为N,那么实际对齐值为==min(M , N)==**「P210」
# 总结-内存对齐
- 目标平台的cpu的32,64
- 目标平台的操作系统32,64
- 编译器本身的的32,64(毫无关系,编译器只完成把代码转换到目标cpu的任务,所以和编译器毫无关系
- 当然,编译器本身32位的话,如果是远古的32位,没有64位的cpu,那他生成的32位
- 编译器目标是32,64
- 这个有影响