[web基础]前后端分离开发+大公司才有的一些设计BFF、graphQL
[web基础]前后端分离开发+大公司才有的一些设计BFF、graphQL
bff的概念我第一次在公司看到后去查了一下,系列的学习了一下,顺路识别一下是不是1个过度设计的技术!
BFF(Backend for Frontend)意思
前端的后端服务层
- 实现1:前端团队自己维护一个后端服务,专门为前端页面定制接口,解决一个接口服务多个端(Web、App、小程序)时的冗余和复杂性。
- 实现2:也可能是后端工程师去维护的1个服务,比如加各种打点
源于 Netflix 的架构演进,用来解决多终端统一接口适配问题。
后来被阿里、美团、字节等公司在大前端架构中广泛实践。
各种场景下怎么说:
- 技术文档/架构图中 常写为:BFF 层 或 前端后端服务
- 口语交流中:一般说“BFF 服务”或“我们给前端单独弄了一个后端层”
其实术语挺乱,还不如叫bff
1、从前后端不分离到前后端分离到极度工业化大公司化设计—出现了bff的概念
早期阶段:前后端不分离(单体架构)
- 比如早期的Java JSP、PHP、ASP.NET 等服务端模板渲染。
- 特点:
- 页面和接口混在一起,当时也没什么前端和后端2个岗位,就1个岗位:web开发工程师
- 可以说当时的前端没有独立开发权,页面由后端工程师渲染生成,比如现在go语言的template模块也是这种产物
当时web本来就没那么繁荣,页面更新慢、体验差,也没多端适配这种概念,甚至当年就只有电脑,都没智能手机!
前后端分离(RESTful API + SPA)
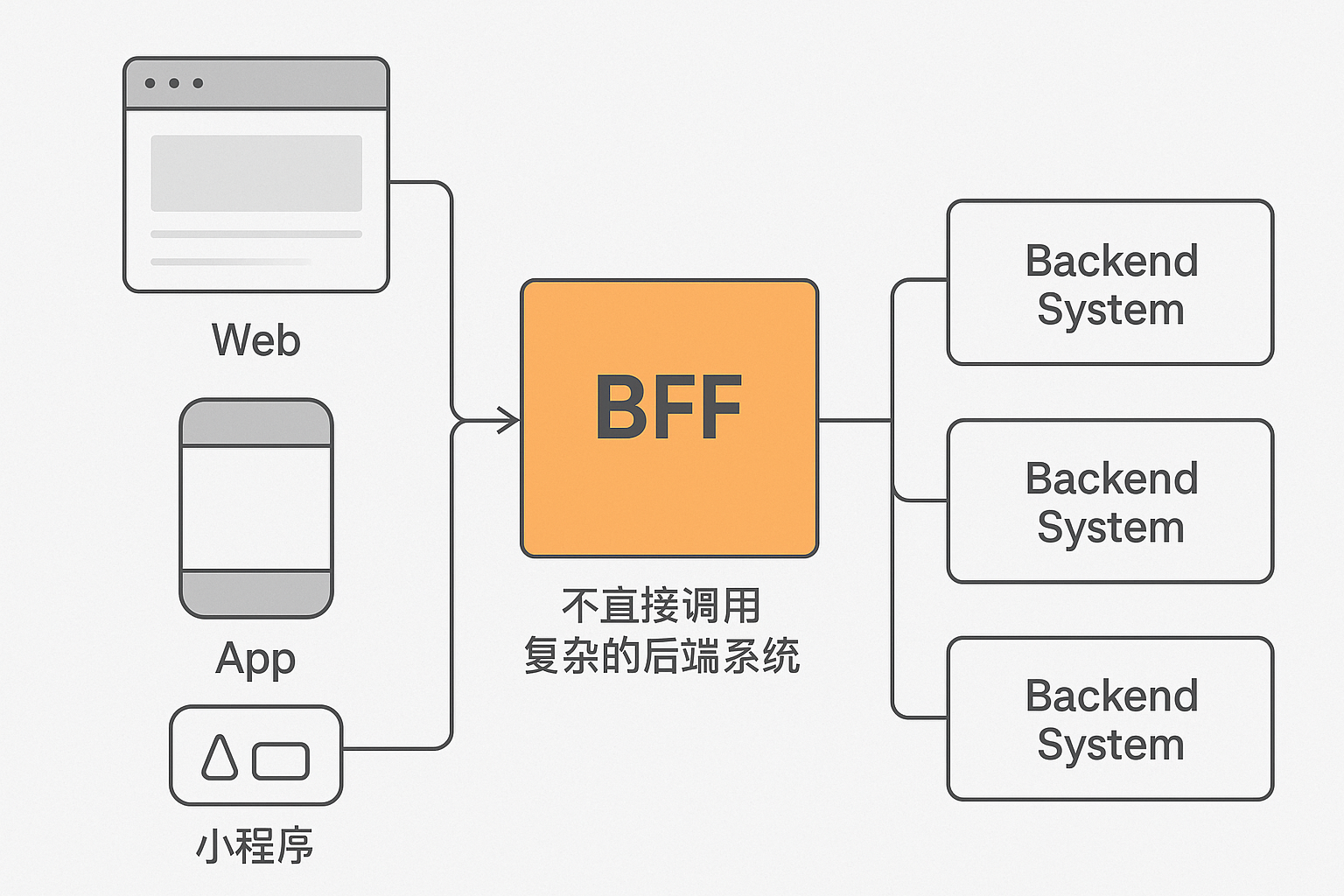
多端时代带来的挑战
- 一个后端接口服务多个终端(Web、App、小程序):
- 各终端需要的字段不一样。
- 展示逻辑不同。
- 调用链复杂、性能压力大。
- 前端需要自己处理拼接、容错、字段兼容等繁琐逻辑。
附录1.和bff有关的1个协议:graphQL
GraphQL的兴起:GraphQL作为一种API查询语言,天然适合作为BFF层,让前端可以精确请求所需数据
GraphQL常被用作实现BFF的一种技术手段,其他实现BFF的方式:
传统的REST API,其实你不写schema也行,直接调某个接口,然后我们直接手动写个聚合接口,还是一样效果【只是扩展性不强】
gRPC、自定义协议
我的疑问:GraphQL是如何被解析查询,调用多个内部微服务API,怎么知道的?
GraphQL如何知道调用哪些微服务是通过开发者预先定义的resolver函数决定的。这些函数明确了每个字段的数据来源,并负责调用相应的微服务API。【其实本质就是看后端工程师太忙了,又有现成接口,只是可能多调几个而已】
GraphQL解析查询并调用微服务的机制,当GraphQL服务器收到一个查询时,会发生以下步骤:
- 解析查询:将GraphQL查询字符串解析为抽象语法树(AST)
- 验证查询:确保查询符合Schema定义
- 执行查询:按需调用resolver函数
GraphQL的强大之处在于:
- 按需执行resolver(只有查询中请求的字段才会触发相应的resolver)
- 并行执行独立的resolver(提高效率)
- 提供统一的查询接口(隐藏后端复杂性)
在BFF模式中,GraphQL服务器充当了前端和后端微服务之间的"智能代理",根据前端的具体需求按需调用相关微服务,这正是GraphQL与BFF结合的关键价值。
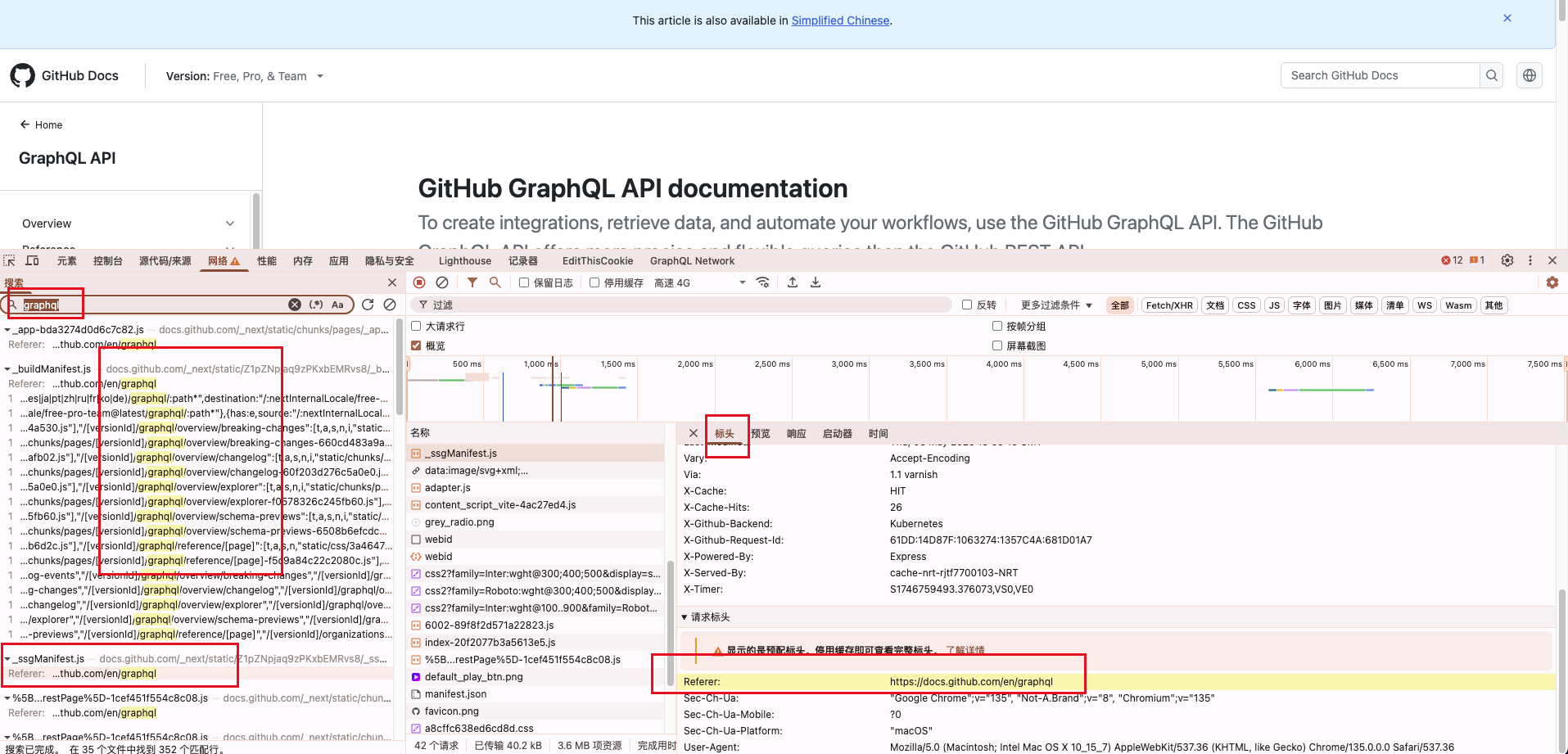
我如何去看前端是否使用了GraphQL,我看chrome浏览器看到的都是http?
虽然GraphQL通常是通过HTTP传输的,但它与普通REST API请求有明显区别!
如何识别前端是否在使用GraphQL:
GraphQL专用标头
有些GraphQL实现会使用特定的HTTP标头:
X-GraphQL-RequestContent-Type: application/graphqlApollo-Query-Name(Apollo客户端特有)请求体(payload)会包含
query或mutation字段
例如,GraphQL请求的payload可能看起来像这样,反正就是1个字:猜用户传递了schema
{
"query": "query GetUser($id: ID!) { user(id: $id) { name email } }",
"variables": { "id": "123" }
}
附录2.和bff可能有关或者邻近的分层:SSR
SSR(Server-Side Rendering,服务端渲染)
首先在大公司,bff可能成立独立团队,也可能业务团队自己维护
ssr基本上是前端自己维护,使用node去在服务器端做解析
附录3.思考:bff是否真的必要?是否有过度设计之嫌!
个人开发者,基本上无必要
大部分公司,基本上无必要
只有下面特征才需要,而且也不是必要:
- 极度复杂,后端api太多,想快速上线,没后端人力支持写单独接口
- 可能需要加一层bff,顺路做grpc或者啥的转发,加打点啥的,反正就是不影响业务逻辑的
- 避免前端发一堆请求过度获取数据,过度暴露接口,安全考虑
- 避免前端发一堆公网请求,延迟高,不如内网先聚合,请求一次即可
反正就是,不要过度设计,每个技术的出现都是为了解决某些问题的!
其实我的理解:不是那么必须
但是对互联网大厂这种级别,确实抽1层bff,方便做很多事情,可能做的收益还是有的!
附录4.现在BFF的主流最佳实践
1、如果需要“隔离复杂性 + 定制接口 + 降低前端负担”**,那就做,如果想要为每个前端(Web、App、小程序)定制的后端服务,做接口聚合、数据裁剪、缓存等,让前端不直接调用复杂的后端系统(比如一堆团队的接口,那么干脆抽一层吧,既然bff也是分层,那么在这层做也行),那就做
2、如果后端没时间做一个综合的接口,那么抽一个bff团队专门维护,专门去调内部api,然后聚合给前端用
3、可能在BFF还做一些风控、打点、数据分析啥的
好的场景举例:
假设你要开发一个用户中心页面:
如果没有 BFF,前端要自己调用这些后端接口:
● 用户信息服务:/user/info
● 用户积分服务:/user/points
● 用户订单服务:/orders/recent
● 用户等级规则服务:/level/rule
● 再做各种拼接、容错、数据结构转换...
结果:
● 请求太多、处理复杂、维护困难。
● 一改后端结构,前端也得改,牵一发动全身。如果有了 BFF,前端只调用一个接口:
GET /bff/user/dashboardBFF 在后台:
- 调多个后端服务,聚合数据
- 解决不同团队的系统认证机制【当然你也可以使用SSO之类解决,那是后话了】
- 只返回前端真正需要的字段(裁剪字段)。
- 处理好异常、加缓存、控制请求频率等。
- 对 App/Web 页面做专门的接口适配
然后让前端写个graphQL就行了