[web基础]前端CSR的情况下反推数据来自特定接口的填充逻辑-前端js代码混淆
2026/1/9大约 3 分钟
[web基础]前端CSR的情况下反推数据来自特定接口的填充逻辑-前端js代码混淆
1、两步就能排查定位到
这是个非常典型的 CSR(Client-Side Rendering)排查问题,“页面上某个框的内容 = 某个接口返回的 JSON + 某段 JS 的映射逻辑”
在 CSR 里,渲染链路一般是:
1、用 DevTools 精确反查:Elements → 获取对应的class选择器,里面的字符串,无论有没有空格
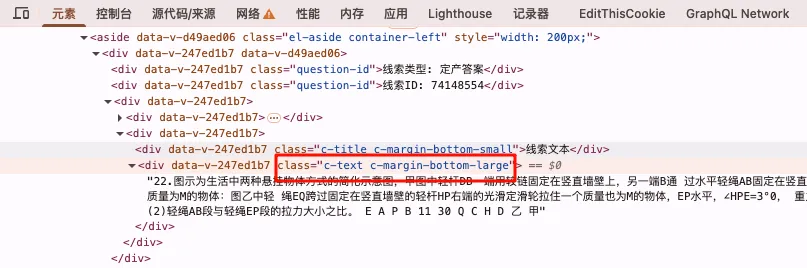
2、Elements → 定位 DOM → 反查 JS
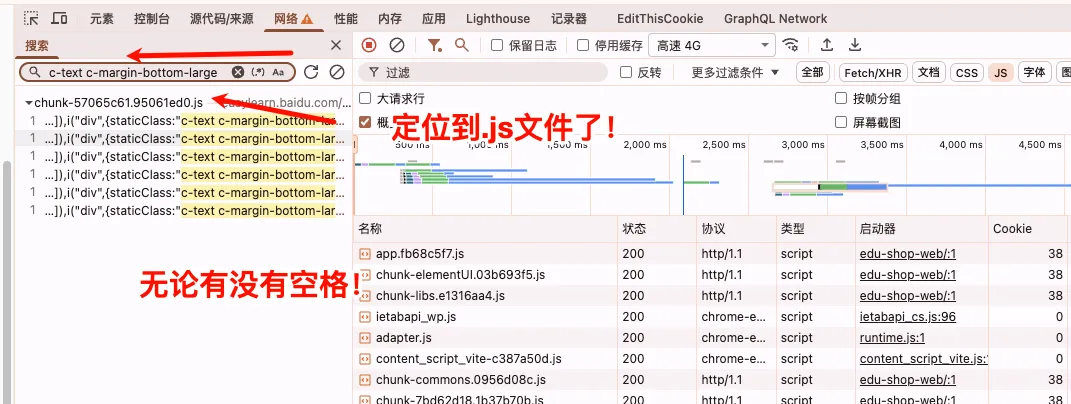
2、CSR只是更加方便从JavaScript定位数据从哪个接口去获取了,但是其实CSR的话,那不是更好别人使用爬虫解析
CSR 并不会让“爬虫更容易”,真正决定爬虫难度的是:
- 权限、风控、反爬策略,而不是 CSR / SSR。
爬虫最怕的 5 件事(按杀伤力)
- 鉴权(Cookie / Token / Session)
- 动态参数 / 签名
- 频控 / 行为分析
- 账号体系
- 数据裁剪(只给你能看的)
3、CSR vs SSR,哪个更容易被爬?
CSR 页面
爬虫要做什么?
- 拿 token / cookie
- 模拟登录
- 生成签名
- 处理分页 / 状态
- 处理限流
接口是清晰了 但门槛还在
SSR 页面【反而更容易 】
爬虫要做什么?
- 直接请求 HTML
- 用 XPath / CSS Selector,不用 JS,不用 token(很多情况下)
反而更容易,很多数据站点最早反而是“HTML 爬虫天堂”
90% 的商业爬虫,更喜欢爬 SSR 页面
原因:
- HTML 不需要逆向
- 不需要 JS 执行
- 不需要接口签名
- 更稳定(字段不常变)
而 CSR 接口:
- 字段经常变
- 参数有校验
- 返回依赖上下文
- 容易封
附录1、CSR情况下:为什么前端返回的.js文件名字很奇怪?demo.js 会变成 deffa4-4obb.js 这种名字
这种混淆典型的比如:Vue 在生产环境将 demo.js 编译成带 hash 的文件名
这是“业界共识”(不是 Vue 独有)
以下工具 全部默认这么做:
Vue CLI、Vite、React (CRA / Next.js)、Webpack
> 因为它同时解决了:性能、缓存、稳定性、运维成本
1、这个vue编译为乱七八糟的js这种混淆还能避免人家一下子就看懂我们源码,然后抄走了?【能“增加成本”,但不能“真正防止”】
混淆只能提高源码阅读成本,真正的核心逻辑仍应放在后端,现在AI时代还能一键改写变量命名!
2、【还能有一个很好的帮助,“最重要的用途”】:避免上线后CDN有缓存,有时候上线后发现莫名不生效,就是因为还要花钱刷cdn
3、原理:
文件名 Hash(内容指纹)
demo.js
↓
deffa4-4obb.js- deffa4-4obb 是根据 文件内容算出来的 hash
- 内容不变 → 文件名不变【还能复用CDN】
- 内容一变 → hash 立刻变 → 新文件名
这叫:Content Hash(内容指纹)
代码压缩 + 混淆
生产环境默认会:
- 去掉空格、换行
- 把变量名 userName → a
- 合并重复代码
- 删除调试信息
目的是:体积更小、加载更快、不方便直接阅读